PySpark for Big Data Processing:


Project information
- Link: Project description and code on Github.
A huge amount of logfile data (12 GB) from a fictional music streaming company is analysed. Apache Spark as a technology for distributed data processing is used.
While Big Data has no universal definition we consider the problem to fall into this domain as it cannot be solved without a network of distributed computers.
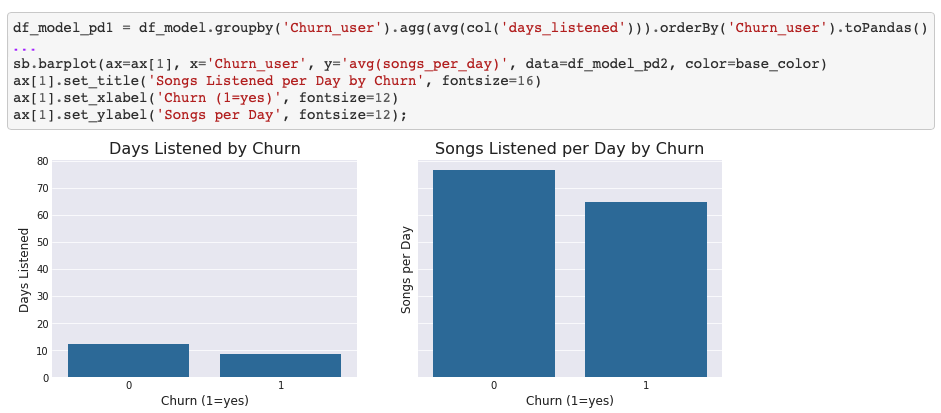
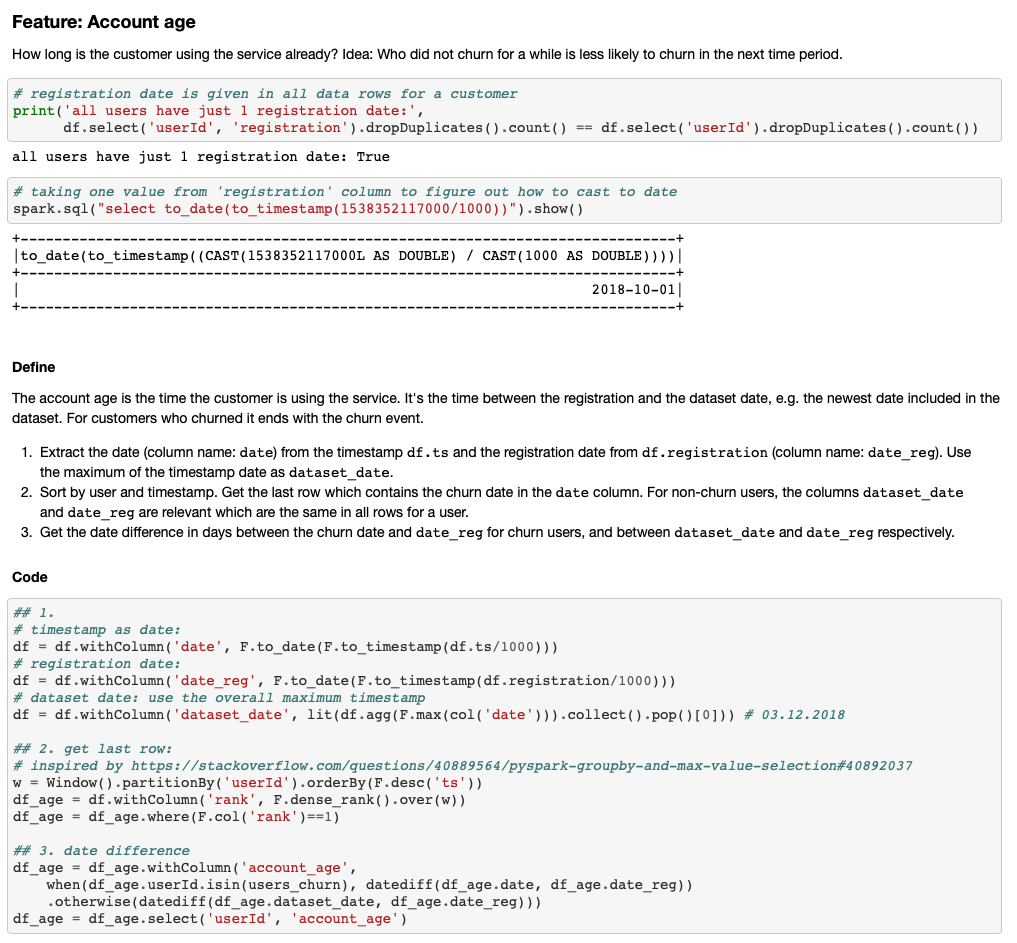
Churn analysis is performed. You'll find the usual steps to load, assess, and clean the data, exploratory data analysis, feature engineering, and modelling. Modelling: we simultaneously test multiple estimators and algorithm parameters to find the best model. Please refer to the Github page for more details.